Luca Passani, CTO @ScientiaMobile
“The golden rule: can you make a change to a service and deploy it by itself without changing anything else?”
― Sam Newman, Building Microservices
Boy. How can I explain to readers what a microservice architecture is in just a few words? If you already know what Microservices are, and I am sure most of you do, please bear with me for the first part of this post. If you don’t, you’ll want to do a lot more reading than this post. This, this and of course Wikipedia are all good starting points.
A Look at the Monolith
Let’s say that you now work for a large organization. The approach where you have a database with all the business information in the middle, with web, desktops and apps dancing around it, may not quite cut it anymore. That architecture is now called a monolith. Monolithic architectures have been the standard in the past, but, in large organizations, they tend to become a bottleneck in terms of maintenance, service availability and further development by geographically distributed teams. The modern way to do things is to have components that work independently and just know the minimum that there is to know when it comes to interacting with other components in the system. This allows complex products to evolve with the support of different teams without the limitations posed by, for example, a database that only a few are allowed to touch. Not only that. Once subsystems know how to cooperate with one another through an agreed protocol, be it RPC, a REST API or whatever, different teams may pick different technologies for the job. Possibly the one they deem the most appropriate or the one they are most experienced in.
This sounds fantastic. And it is. But it comes with quite a lot of aggravation too. Working independently is great, but how do you know that updating one component won’t negatively impact the whole system? How do we make sure that the environment that an engineer is using on their laptop is 100% compatible with the one in which their code will run once deployed in testing and production? These (and more) are all big questions. Those are the questions that led to the introduction of Modular architectures, Continuous Integration, Continuous Delivery, Virtualization, Containerization, Docker, DevOps and a lot of other things. A scary list of new names and concepts.
Device Detection within a Microservice Architecture
How does device detection, and WURFL specifically, fit in a microservice architecture?
One way to look at it is that, as long as pretty much any WURFL product is concerned, no one is prevented from using WURFL in a microservice architecture. Just download the libraries and the wurfl.xml from your customer vault, add the files to your Git and you can build and run your device-aware subsystem just like you do with your own proprietary code. This works. Yet, the onus of making sure that the API is periodically updated and that the WURFL updater is correctly configured would fall on the engineer and the DevOps.
A different approach that would more closely embrace the microservice spirit calls for a device detection subsystem that comes alive as part of an automated deployment procedure, that always deploys with the latest API and always contains the latest data. What we are announcing today is exactly that. We have a new product that will fit perfectly in the environment of organizations that have adopted microservices as their way to run and manage complex systems.
During development, we used “WURFL Private Cloud” as the internal name for the product. And that was a good name in a way, because it did describe what the product is: a mechanism that can be deployed in their internal network to fulfill the device detection needs of the whole organization. In the new product, API and data updates just happen as part of the normal deployment cycle. Companies no longer need to worry about manually updating the data nor the API.

Figure 1: The WURFL Microservice REST HTTP Server interacts with local APIs and handles data updates transparently.
On the other hand, though, the “Private Cloud” name wasn’t that good. The term “Cloud” immediately suggests that there’s a hard dependency on something “out there”, managed by a third-party. This is not exactly the case with WURFL Microservice. Once deployed, the product will run 100% in the customer’s infrastructure. We needed a name that better captured the essence of our new creature. That essence is that WURFL is now available as a Microservice component. AWS and Docker users can make Device Detection play by the same rules as pretty much any other Microservice component out there. Add a few lines to your deployment scripts and the latest and greatest WURFL will be available to serve the device detection needs of your organization, be they related to either the AdTech, Analytics or Web Optimization use-case.
I will discuss our Docker offering in a future installment. Let’s focus on AWS for now. If you are an AWS user, you may be familiar with the AWS marketplace. That’s the place where you can buy software from over one thousand companies with one click and deploy it on your EC2 instances. ScientiaMobile is now one of those AWS vendors. Type WURFL in the AWS Marketplace search box and this is what you’ll get:

We support several popular programming languages: Java, .NET (C#), PHP, Node.js and Golang. Assuming your organization is a Java shop, you’ll probably want to look at the AMI (Amazon Machine Image) that supports Java API clients:

Users can launch the AMI with one click and Amazon will deploy a fully functioning instance of the WURFL Microservice. First time users will need to obtain the client API libraries (in this case Java) directly from the AMI instance through HTTP. More information here:
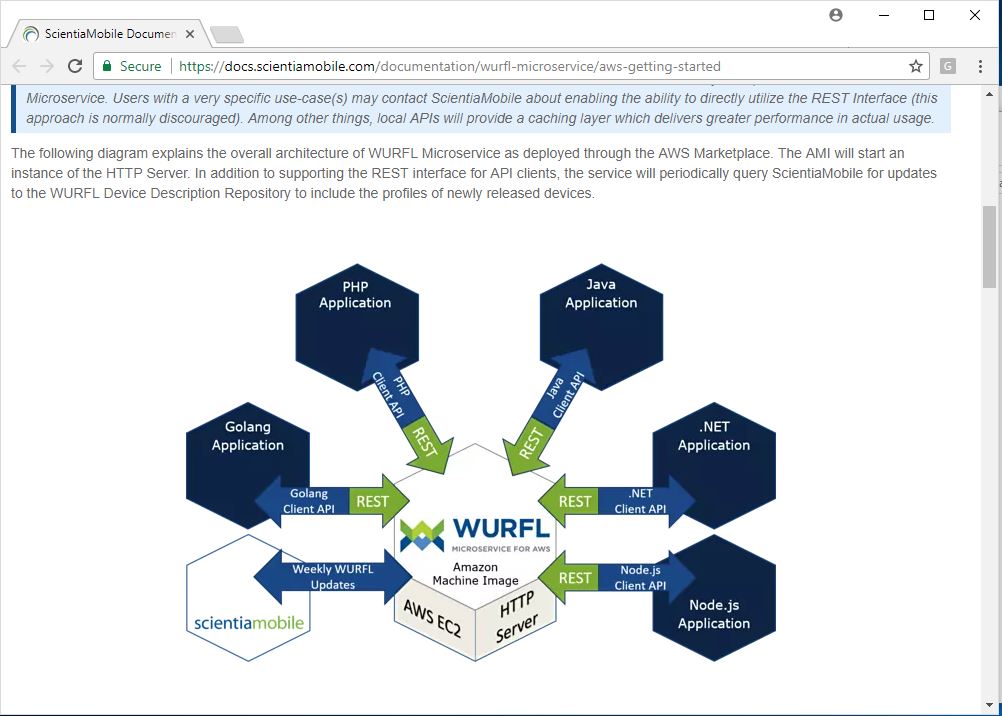
Local APIs are needed to implement local caching layers in the applications that talk to the WURFL Microservice component. This is what allows tens of thousands of detections per second.
In addition to support for different languages, there are three AMI families: Basic, Standard and Pro. The main difference is the subset of WURFL capabilities supported by each. Basic has been designed with the Web Optimization use case in mind. Standard is for AdTech, while Pro is for Analytics. Of course your mileage may vary and every company has their own specific needs. An AdTech company may still want to use the Analytics capability set (Pro AMI), while Basic may suffice for simple analytics. Just look at the WURFL for AWS capability page and decide what is good for you.

Finally, if you have a large organization and require support for multiple languages, the WURFL Microservice Pro edition is for you. Support for 5 languages is included in the package!







