Luca Passani, CTO @ScientiaMobile
![]()
“The golden rule: can you make a change to a service and deploy it by itself without changing anything else?”
― Sam Newman, Building Microservices
Today, we launched WURFL Microservice for Docker, an extension to the WURFL Microservice product line that we already have for AWS. If you are not familiar with microservices, I recommend that you read this post to make sense of why a WURFL REST API server may be a good idea and why Docker can be a great option for deploying it. In extreme synthesis, adopting a microservice architecture is about splitting up complex systems into software components that speak to one another, with each component only concerned about delivering a coherent set of functions. This is the alternative to old-style “monolithic” applications that depend on a complex “omniscient” database at the center of everything (and, as such, also prone to represent a bottleneck at different levels).
In this context, WURFL Microservice is the evolution of WURFL that turns it into an independent component with a single concern: delivering device information to other components in the system.
Device Detection within a Microservice Architecture
WURFL Microservice for AWS explains the use of an “oracle” containing all the device knowledge that different parts of an organization may require. A lot of what you find in that document applies to WURFL Microservice for Docker too. The crossroad is the deployment procedure. While the AWS product assumes that an AWS Machine Image (AMI) is deployed through the AWS marketplace, WURFL Microservice for Docker is about downloading, deploying and starting an (almost) identical WURFL server from the ScientiaMobile private Docker repository.
Some Words about Docker
If you are not familiar with Docker, I’ll try and explain it as simply as I can. Imagine you just got a new laptop. Downloading, installing and configuring software will consume the better part of one or two workdays. If you are a programmer, you’ll think that the problem is solved with package managers, i.e. tools such as NuGet, apt-get and the like. While those tools facilitate the process, you still need to be there and provide the command-line instructions to download and install each single piece. Still quite a lot of work.
Now imagine that you have to buy and configure a computer often. Every week, or even every day. The job would become pretty tedious also with package managers. But what if you had a single script that could:
- Download a fully configured set of your software components
- Apply your standard configuration to each component
- Deploy them on the server you indicated
- Start all the services so that they are immediately ready for use
Sounds like magic, no? That’s the wonderful world of Docker. Docker is, at its core, the ability to package a lot of software into a single image and deploy it into a “container”, i.e. a “slice of server” that feels just like a fully-fledged server to the software running in it.
Note for the nitpickers: of course, an IT guy in charge of configuring computers would probably use disk cloning technology to configure users’ laptops in one fell swoop. But that was not the point I was trying to make. The point is that a developer may still want to spin up a development environment in a container without having to install and configure a Virtual Machine or other software. A container is a quick and elegant solution to achieve this.
Note: on Virtual Machines at this point, if you think that a container is a Virtual Machine, you are not too far from reality, but I don’t want this brief introduction to Docker to get too sidetracked. Let’s say that a container is a Virtual Machine that makes some very significant compromise on the supported OS, while, at the same time, enabling us to run 12 virtual servers on the same hardware that would only support 2 or 3 concurrent Virtual Machines. A pretty good deal.
On top of these core capabilities, the Docker community has created public repositories of pre-built server images called Docker Hub.
Need a load balancer? You just need to look up, say, “HAProxy” in the Docker Hub.
Want a web server? NGINX should do.
In its simplest form, deployment and installation of an NGINX image is as easy as: $docker pull nginx
This will give you a fully functioning virtual server that will work out of the box in production, in a test environment, or on your laptop running support for Docker development.
Of course, a series of such commands can be combined in a Dockerfile to, for example, install GoLang, add dependencies, download your proprietary code from a Git repo, deploy a load balancer and so on. Existing images can also serve as the basis for customized images tailored for the specific needs of an organization.
If all this sounds very powerful, it’s because it is. This is the technology that has created DevOps and a whole DevOps culture. Quoting from https://aws.amazon.com/devops/what-is-devops/ :
“DevOps is the combination of cultural philosophies, practices, and tools that increases an organization’s ability to deliver applications and services at high velocity: evolving and improving products at a faster pace than organizations using traditional software development and infrastructure management processes. This speed enables organizations to better serve their customers and compete more effectively in the market.”
Thanks to Docker (and to similar and additional tools in the DevOps and microservice spaces), a developer using a Macbook, a test environment running on a local physical ‘bare-metal’ Linux server at the office and the production servers in the Cloud will all run the application in virtually (no pun intended) identical environments (minus the ability to scale, of course). Those who have been in IT for some time will recognize the quantum leap from a time when slightly different application environments would cause deployment nightmares: different OS versions, different PHP/JVM versions, missing dependencies, and so on.
WURFL and Docker: Getting Started
Given the commercial nature of WURFL, committing a working image of WURFL Microservice to Docker Hub was not viable. What we did instead was set up our own ScientiaMobile “Docker registry”, i.e. a ScientiaMobile repository of Docker images. We also made sure that ScientiaMobile customer credentials could be used to access WURFL Microservice images through SSO with our Docker registry. In short, customers who acquired a WURFL Microservice for Docker license can now deploy it with the following commands:
docker run --name wurfl-microservice.server --rm -p 8080:80 \ -v /tmp/wm-server-logs:/var/log/wm-server \ -e WM_CACHE_SIZE="200000,50000" \ -e WM_MAX_CORES=7 \ -e WM_ACCESS_LOG_TO_FILE=true \ -e WM_ERROR_LOG_TO_FILE=true docker.scientiamobile.com/<license_id>/wurfl-microservice.server
and confirm that the REST server is running with:
$ curl http://localhost:8080/v2/status/json { "lookup_request": 0, "lookup_useragent": 2, "lookup_device_id": 0, "make_model_requests": 0, "server_info_requests": 3, "v1_capabilities_requests": 0, "not_found_404": 0, "server_uptime": 23171 } $
Back to Microservices
That was a lot of talking about Docker. Back to the main question now. How does device detection, and WURFL specifically, fit in a microservice architecture?
As long as pretty much any WURFL product is concerned, no one is prevented from using any WURFL product in a microservice architecture. Just download the libraries and the wurfl.xml from your customer vault, add the files to your private Git repo and you can build and run your device-aware subsystem just like you do with your own proprietary source code. This works, but the onus of making sure that the API is periodically updated and that the WURFL updater is correctly configured would fall on the engineers and the DevOps.
A different approach that would more closely embrace the microservice spirit calls for a device detection subsystem that comes alive as part of an automated deployment procedure, that always deploys with the latest API and always contains the latest data. During development, we used “private cloud” as the handle to refer to the product. And that was a good name in a way, because it did describe the solution from a technological viewpoint – a mechanism that can be deployed in their internal network to fulfill the device detection needs of the whole organization. In the new product, API and data updates just happen as part of the normal deployment cycle. Companies no longer need to worry about manually updating the data nor the API.
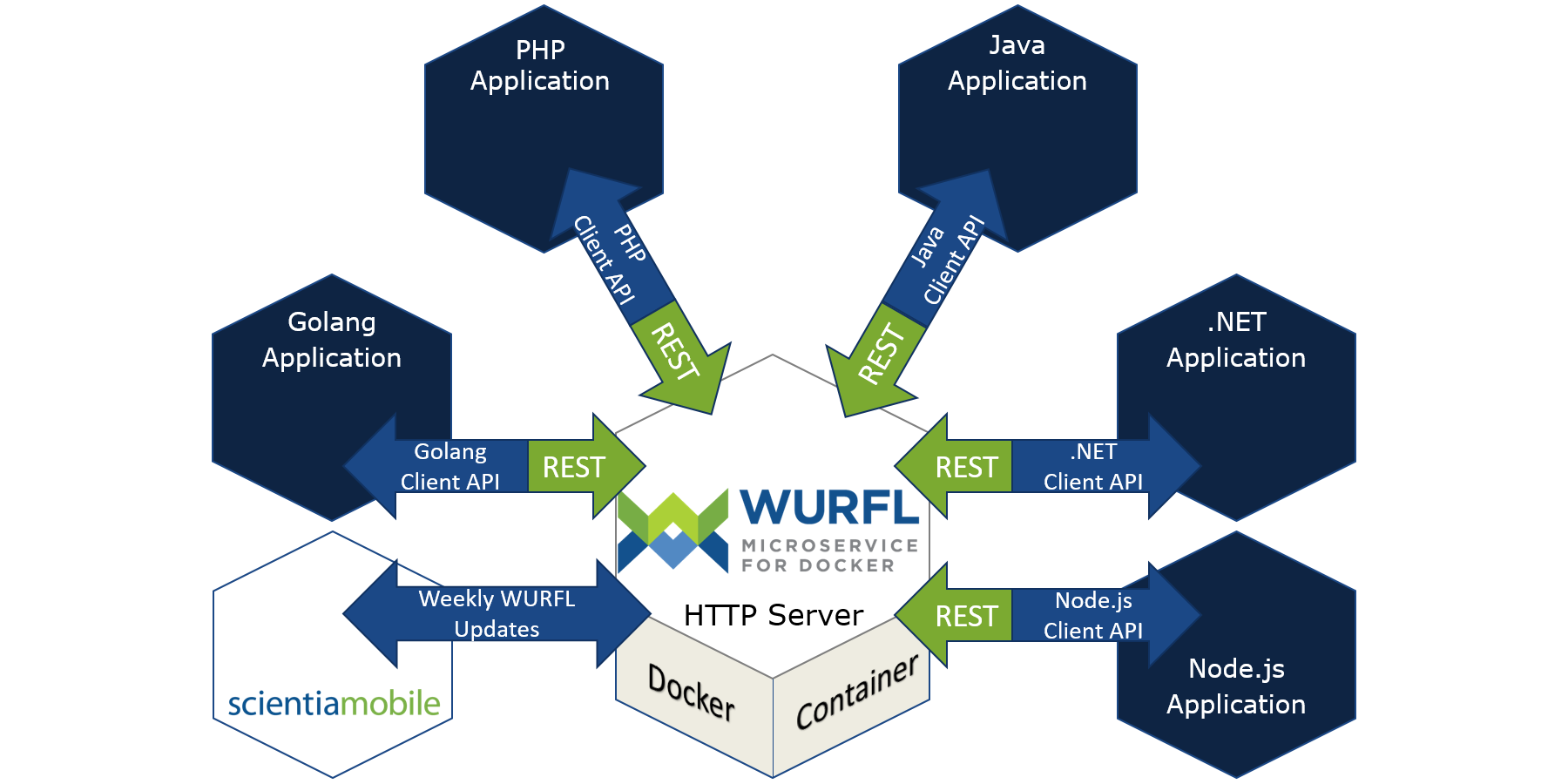
Figure 1: The WURFL Microservice REST HTTP Server interacts with local APIs and handles data updates transparently.
On the other hand, though, “private cloud” wasn’t a good product name from a marketing perspective. The term “Cloud” immediately suggests that there’s a hard dependency on something “out there”, managed by a third-party. This is not exactly the case with WURFL Microservice. Once deployed, the product will run 100% in the customer’s infrastructure. We needed a name that better captured the essence of our new creation. The final name was WURFL Microservice, i.e. a name that brings ease of integration between the new product and other microservices into focus.
Docker users can now make Device Detection play by the same rules as pretty much any other Microservice component out there. Add a few lines to your Dockerfiles and the latest and greatest WURFL will be available to serve the device detection needs of your organization, be they related to either the AdTech, Analytics or Web Optimization use-case.







