Apache NiFi is an open-source framework for data flow management, transformation and routing. If you are already familiar with Extract, Transform and Load (ETL) concepts, you’ll feel right at home with NiFi.
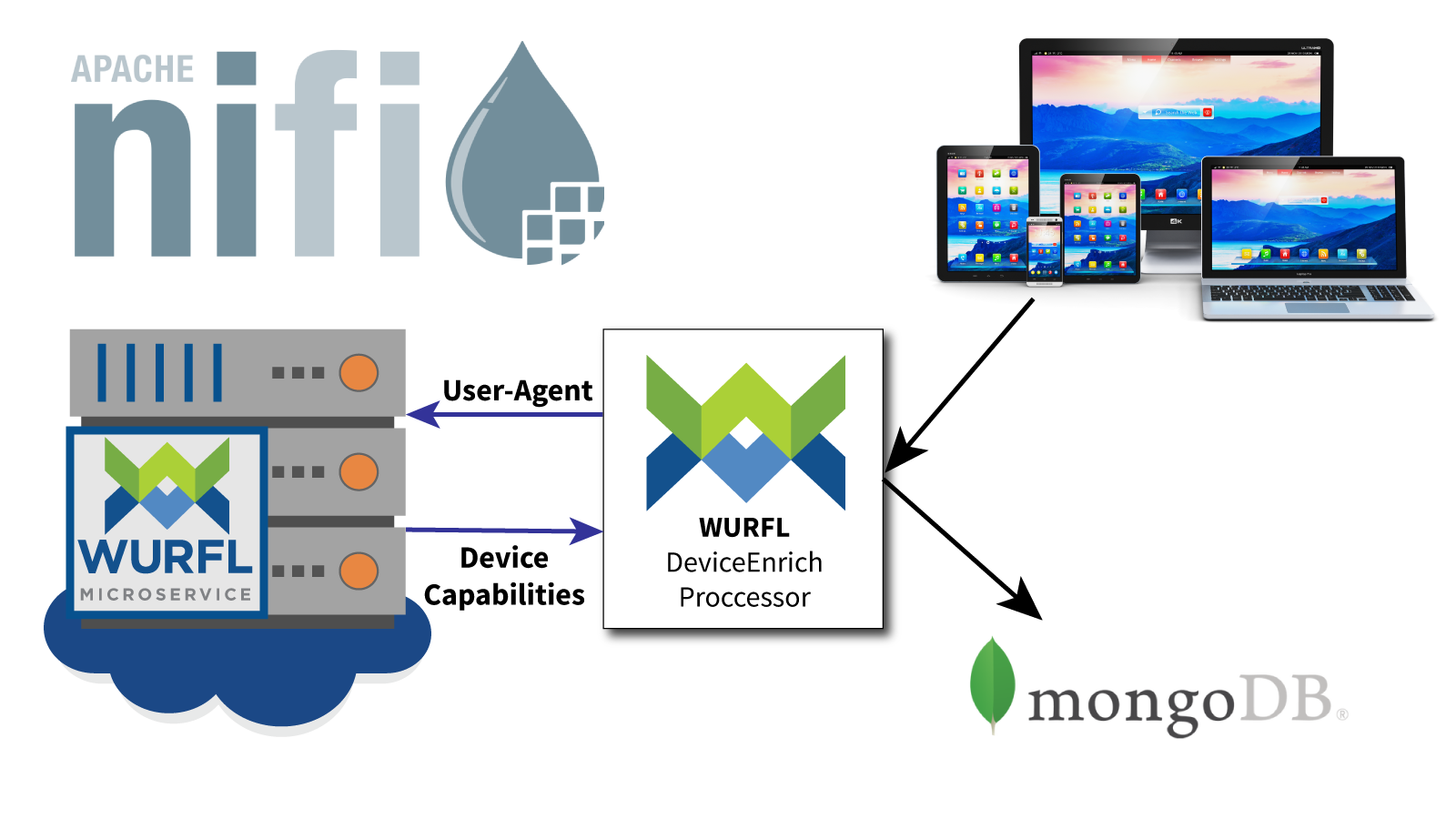
A big part of NiFi’s power comes from a wide library of extensions that make it highly customizable. In past articles, we showed how popular frameworks for managing and analysing data could be enriched with WURFL device information. In this article, we will show you how to enrich a NiFi data flow, making device information available to systems that store or consume data downstream.
This post assumes you have a basic understanding of Apache NiFiand some of its core concepts such as FlowFiles, Attributes, Processors and Relationships. Understanding of User-Agent strings and HTTP headers is needed, while familiarity with the basic concepts of Device Detection and WURFL are a plus.
Prerequisites and Conditions
WURFL is an API that retrieves information about device capabilities and features. The WURFL API provides accurate and fast information about tens of thousands of mobile device profiles. The typical use case utilizes HTTP request headers as the key to retrieve device information.
To reproduce the configuration discussed in this article, you will need the following software components:
- Java 8 or above
- Apache NiFi 12.x
- MongoDB 4.x
- WURFL Microservice client Java 2.1.2 or above
- A WURFL Microservice instance (obtainable from the AWS, Azure, or Google Cloud Platform marketplaces, or directly from ScientiaMobile in the form of a Docker image).
- ScientiaMobile’s
WURFLDeviceEnrichProcessorextension for NiFi (source code available here).
Demo Use Case
Our demo handles data files containing HTTP request headers. We are going to enrich those files with WURFL device information that will subsequently be stored in MongoDB. A sample data file can be found here. The process consists of the following steps:
- Load the file into Apache NiFi
- Split the file content into a set of single JSON HTTP requests.
- Create a NiFi flow file for each request and add HTTP headers as attributes.
- Use the WURFL device enrich processor to add WURFL data to each flow file.
- Transform the flow file with the new attributes into a JSON record.
- Send the JSON record to a MongoDB collection and, at the same time, log the enriched data to NiFi log file.
Data Flow Diagram
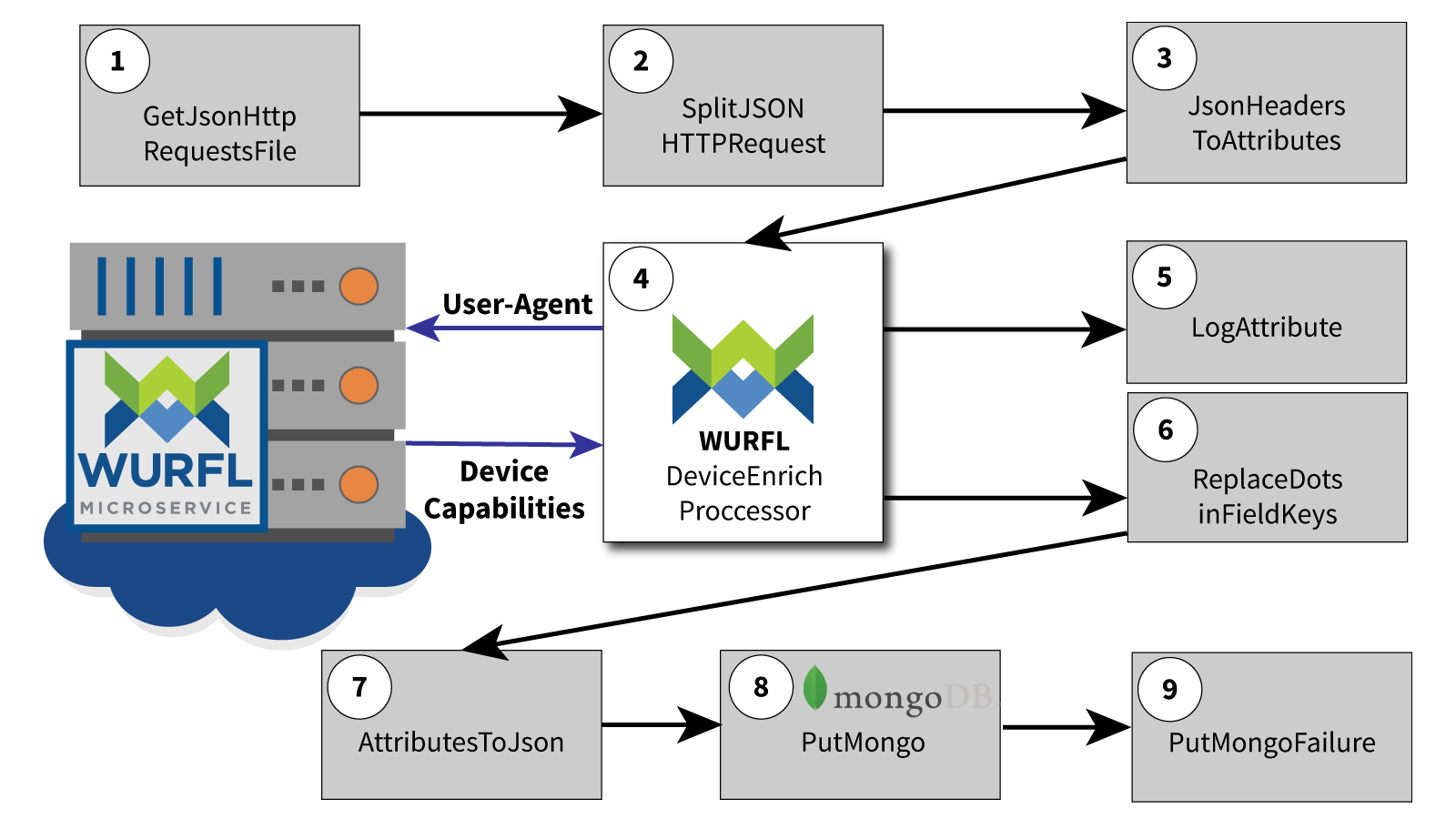
Each block represents a step in our processing pipeline. Let’s examine each single step and illustrate how to configure it.
Note: You can open each flow step and access its setup wizard by double clicking on it in the NiFi UI. Here is a high resolution image of the NiFi Flow.
1. GetJsonHttpRequestsFile
First step: we create a NiFi processor to read a file containing a JSON array of HTTP request headers (again: you can find a sample data file here).
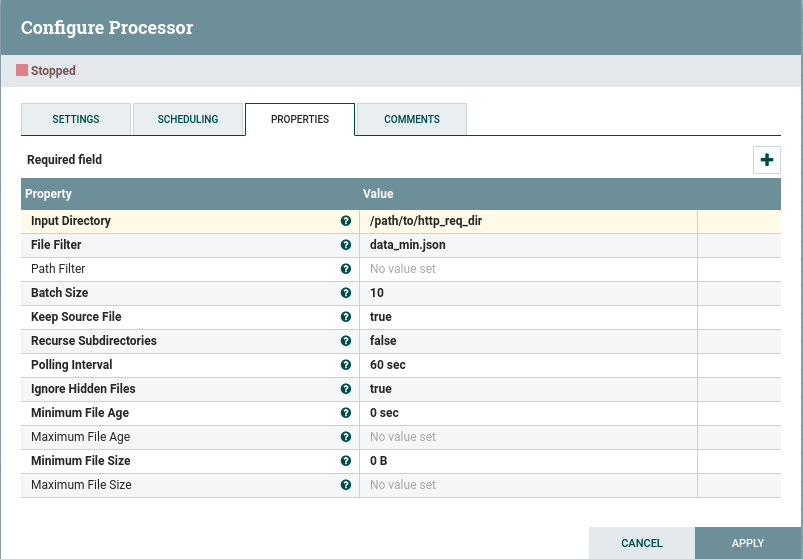
In our case, as we are only using a single example file, we simply configure the input directory and set the file name in the file filter field. The Keep source file field is set to false by default (i.e. the most common option used in production) as you don’t normally want to import your data multiple times. For the objectives of this article, though, you probably want to set this option to true to avoid losing our sample data while we test our flow.
This processor creates a FlowFile and stores the JSON data in it.
2. SplitJsonHttpRequest
The SplitJsonHttpRequest processor splits the data contained in the initial FlowFile into a set of FlowFiles, each one containing a single HTTP request in JSON format. An example of a splitted piece of JSON is:
{
"Accept-Language": "en-US",
"Accept-Encoding": "gzip, deflate",
"X-Forwarded-For": "223.185.182.43",
"Accept": "*/*",
"User-Agent": "Mozilla/5.0 (Linux; U; Android 4.2.2; en-US; Karbonn Titanium S5 Plus Build/JDQ39) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.108 UCBrowser/12.13.5.1209 Mobile Safari/537.36"
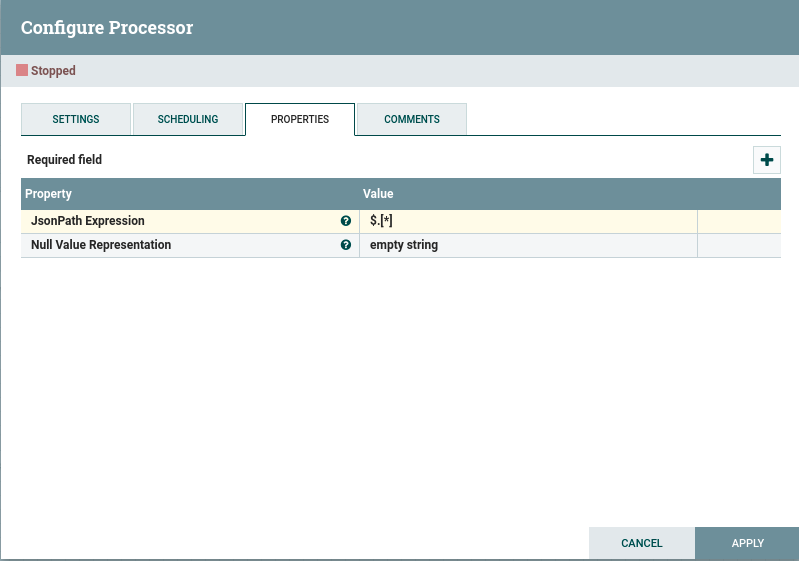
The JsonPathExpression field is set to the JSON path expression that splits JSON objects into the elements under its file root.
JsonHeadersToAttributes
This processor executes a simple groovy script that takes the JSON objects from the previous processor and converts them into a set of FlowFile attributes whose name is prefixed by “http.headers” (you can also find the script here):
import org.apache.commons.io.IOUtils import java.nio.charset.* def flowFile = session.get(); if (flowFile == null) { return; } def slurper = new groovy.json.JsonSlurper() def attrs = [:] as Map<String,String> session.read(flowFile, { inputStream -> def text = IOUtils.toString(inputStream, StandardCharsets.UTF_8) def obj = slurper.parseText(text) // this script has been used to extract HTTP headers, thus the prefix "http.headers." added to the attributes // you can easily generalize this. obj.each {k,v -> attrs["http.headers." + k] = v.toString() } } as InputStreamCallback) flowFile = session.putAllAttributes(flowFile, attrs) session.transfer(flowFile, REL_SUCCESS)
Note: While Groovy scripts are popular among NiFi users, NiFi supports a wide array of other languages, such as: python, jython, jruby, ruby, javascript, lua, luaj and clojure.
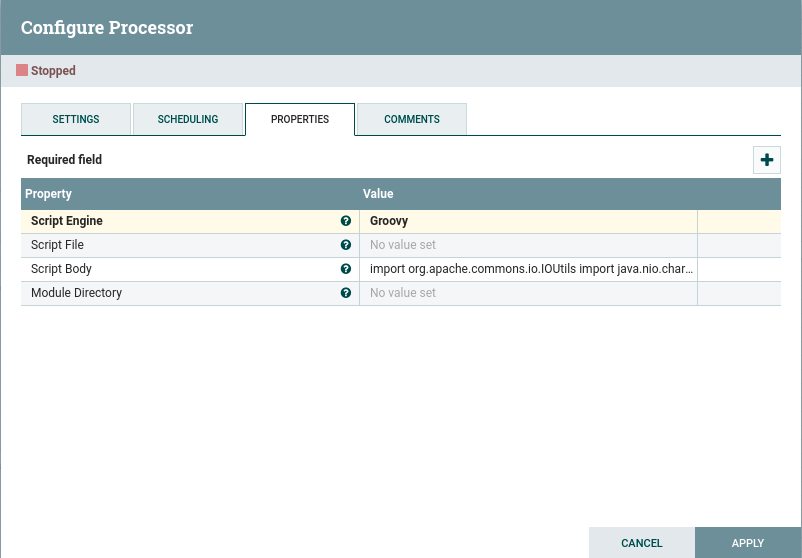
You can either copy the code into the field ScriptBody or paste it into a file and reference the full path in the Script File field. The Script Engine field must be set to Groovy in our case.
4. WURFLDeviceEnrich Processor
This is the core part of our data flow, the step in which we enrich the FlowFile attributes with WURFL device capabilities. The WURFL enrich processor uses an instance of the WURFL Microservice Java client to perform its device detection logic, so we need to configure it.
Note: this WURFL Microservice for Docker getting started guide will give you an idea of how the server component of WURFL Microservice (WURFL Microservice server) is installed. You can also obtain the server component from the AWS, Azure and GCP marketplaces.
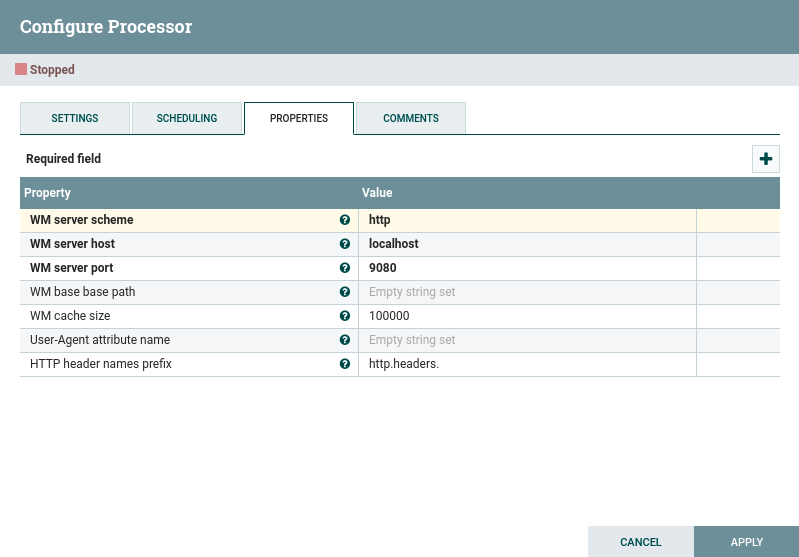
All parameters whose name start with the prefix WM are initialization parameters of the WM client: with the exception of the cache size, they must all refer to a running instance of WURFL Microservice server.
At least one of the User-Agent attribute name or HTTP header names prefix must be set.
The User-Agent attribute name one covers the case in which User-Agent is the only HTTP header available in our flow file attributes. In this case, set the field to the exact name of the attribute.
On the other hand, if several HTTP headers are available as FlowFile attributes, we rely on the HTTP header names prefix. In our example, this is our choice, and we pick “http.headers.” as the common prefix that we have added to FlowFile attributes in the previous step. As a result, the WURFL DeviceEnrichProcessor will load all attributes whose name starts with that prefix. This approach is common in NiFi, as it allows to handle a varying number of HTTP headers (no need to specify which). Other Processors use this mechanism.
5. LogAttribute
From this step on the data flow follows two different subpaths. Let’s take a look.
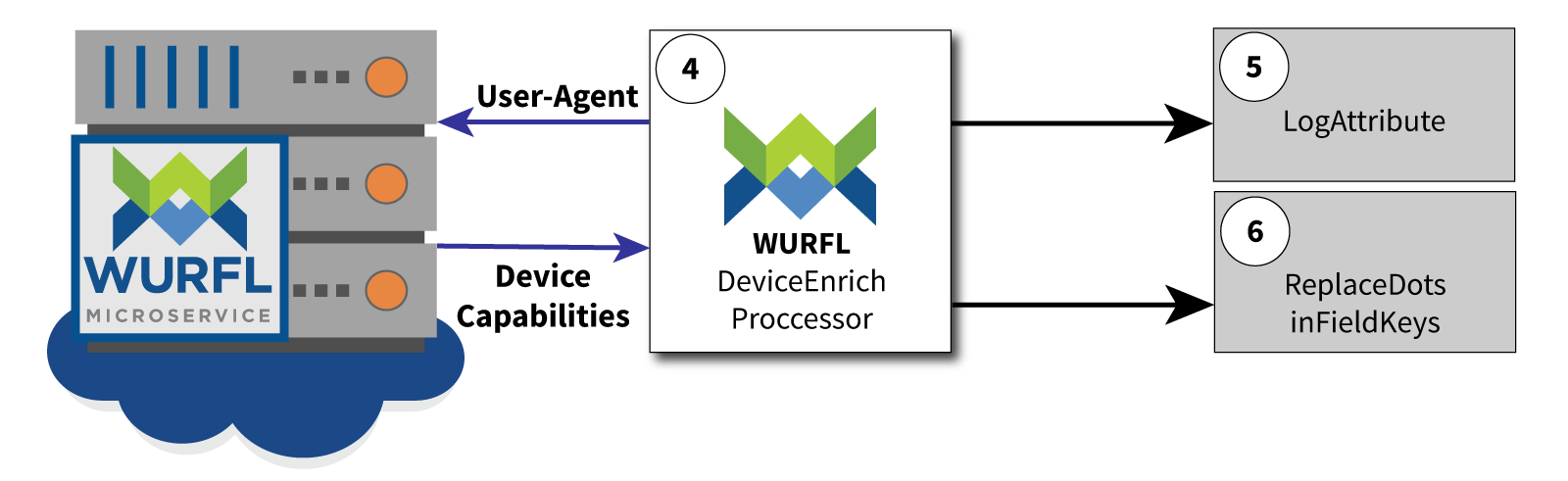
After the WURFLDeviceEnrich processor is done, data “flows” to the LogAttribute processor (in case of both success and failure) and to the ReplaceDotsInFieldKeys processor (only in case of success). LogAttribute simply logs the content of the FlowFile attributes to the NiFi standard log file (you can find it under $NIFI_HOME/logs/nifi-app.log). This is useful if we want to take a quick look at our device detection data. Logged device attributes will look like this (some attributes have been omitted for brevity):
-------------------------------------------------- Standard FlowFile Attributes Key: 'entryDate' Value: 'Thu Jan 21 09:44:49 CET 2021' Key: 'fileSize' Value: '306' FlowFile Attribute Map Content Key: 'absolute.path' Value: '/path/to/dev/' Key: 'file.creationTime' Value: '2021-01-21T09:37:21+0100' Key: 'filename' Value: 'data_min.json' Key: 'http.headers.Accept' Value: '*/*' Key: 'http.headers.Accept-Encoding' Value: 'gzip, deflate, br' Key: 'http.headers.User-Agent' Value: 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_3_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 Instagram 124.0.0.11.473 (iPhone10,4; iOS 13_3_1; zh_TW; zh-Hant; scale=2.00; 750x1334; 192646147)' Key: 'path' Value: '/' Key: 'segment.original.filename' Value: 'data_min.json' Key: 'wurfl.brand_name' Value: 'Apple' Key: 'wurfl.complete_device_name' Value: 'Apple iPhone 8' Key: 'wurfl.form_factor' Value: 'Smartphone' Key: 'wurfl.is_full_desktop' Value: 'false' Key: 'wurfl.is_mobile' Value: 'true' Key: 'wurfl.is_phone' Value: 'true' Key: 'wurfl.is_robot' Value: 'false' Key: 'wurfl.is_smartphone' Value: 'true' Key: 'wurfl.is_smarttv' Value: 'false' Key: 'wurfl.is_tablet' Value: 'false' Key: 'wurfl.is_touchscreen' Value: 'true' Key: 'wurfl.marketing_name' Value: '' Key: 'wurfl.model_name' Value: 'iPhone 8' Key: 'wurfl.wurfl_id' Value: 'apple_iphone_ver13_3_subhw8' --------------------------------------------------
6.ReplaceDotsInFieldKeys
This step is another ExecuteScript step that runs the following groovy code:
import org.apache.commons.io.IOUtils import java.nio.charset.* def flowFile = session.get(); if (flowFile == null) { return; } def oldAttrs = flowFile.getAttributes() oldAttrs.each {k,v -> new_k = k.replaceAll("\\.","_") session.putAttribute(flowFile, new_k, v) session.removeAttribute(flowFile, k) } session.transfer(flowFile, REL_SUCCESS)
This code replaces all the dots characters in the attributes names with underscores in order to make them usable as field names for MongoDB records, whose collections do not accept dot (“.”) characters in field names. You can find the code here too.
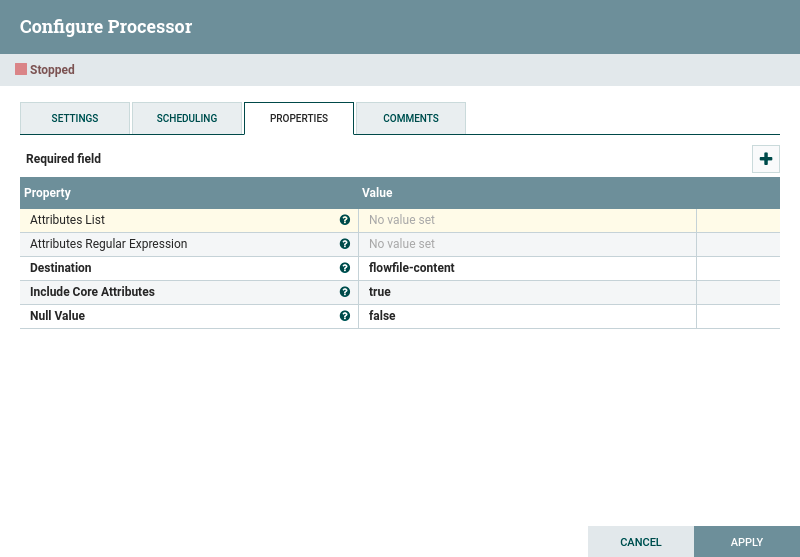
7. AttributesToJson
This processor transforms a set of attributes froma FlowFile into a JSON key/value entity. We select all attributes by simply leaving the property AttributeList empty. The JSON is set in the FlowFile content field.
The JSON content can now be added to a MongoDB collection.
8. PutMongo
This process sends a FlowFile JSON content to MongoDB.
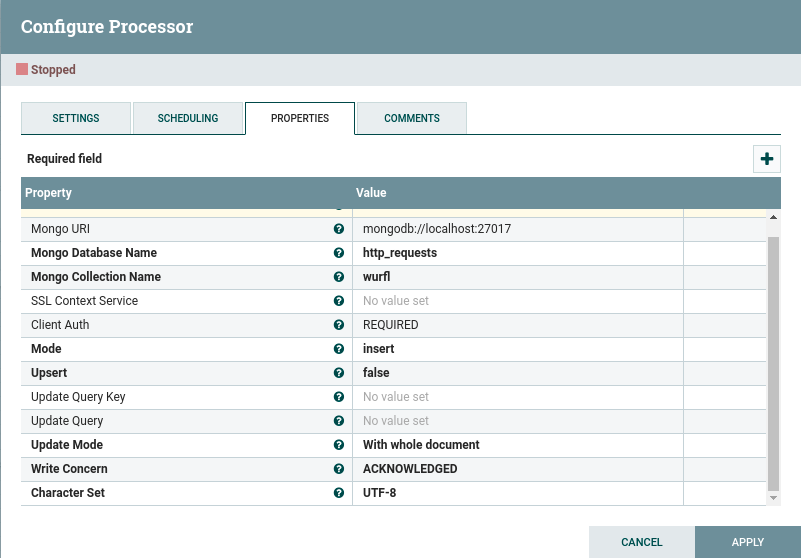
As a minimum, we need to provide NiFi with the following information: MongoDB connection parameters, database and collection names (the Processor will create them if they don’t already exist).
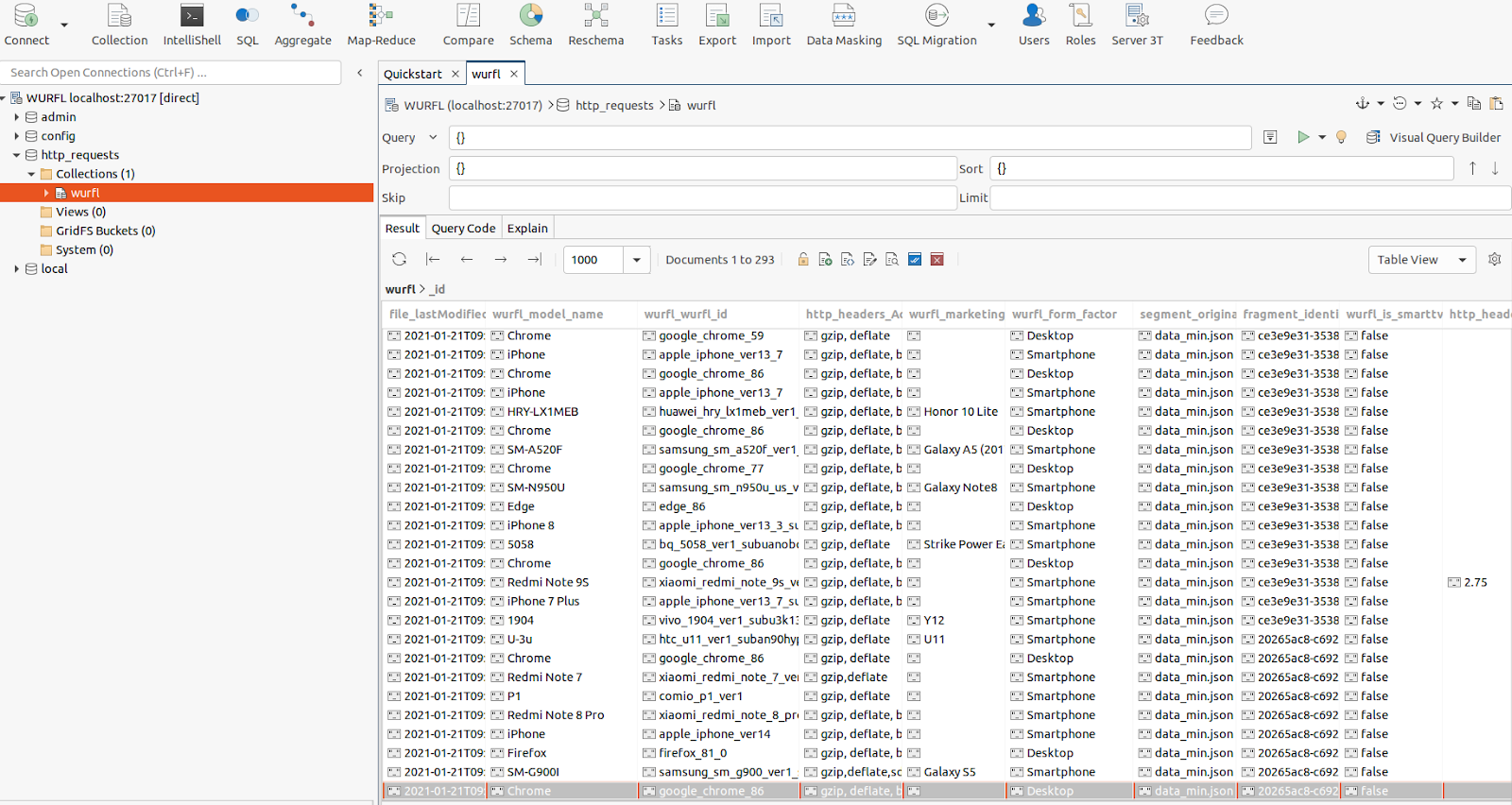
Accessing our MongoDB instance through its GUI confirms that all the records (containing our HTTP request headers and WURFL data) have been correctly uploaded. If there are failures, then they will be logged (step 9).
Conclusions
NiFi is a neat ETL tool for managing complex data flows in an organization. In this article we showed how the two technologies can easily be made play together.
Wherever there is HTTP data, WURFL can enrich it with device information to provide more insights.







